I am a huge PowerShell fan, and pretty much anybody who knows me is aware of that.
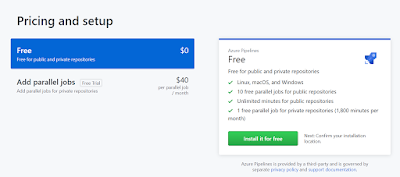
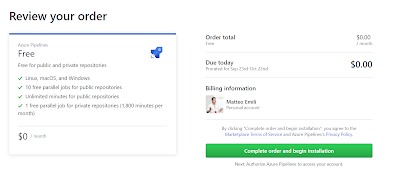
Over time I developed my set of scripts for demos and conferences, and some of them are in use in my homelab on a regular basis. One of them is for managing Azure Traffic Manager, and I realised that there is no Azure DevOps task for managing Traffic Manager on the marketplace! Thanks to the brilliant session Utkarsh did at the London Microsoft DevOps Meetup I decided to give a go at at converting that script.
So this is what I did to recycle my script in a task - beware: this post is a crash course on how to do that, and I don't think it is actually anything special. It is just an easy way of productively recycle some existing scripts in a good way. I haven't finished yet - as a good Product Owner I started with an MVP and I see there is more and more to add to it 👀 - but it is slowly coming together and I hope it can be useful to someone in the near future.
What you need to do is create the scaffolding with the tfx cli. from which you can start customising the script.

Then remove any reference to the JavaScript portion of the task - you are just recycling a PowerShell script so you don't need it! It will also save you time when debugging it as otherwise the runner defaults to the JavaScript entry-point. Needless to say, the name of the target script is going to be the name of your script.

Add the VstsTaskSdk module otherwise you are going to get odd errors out. Also, remove any versioning reference. The structure should be .../ps_modules/VstsTaskSdk. This is true for every module you are going to use:

Code-wise, keep the scaffolding as clean as you can, and add your script inside the try statement after the Trace-VstsEnteringInvocation $MyInvocation. You should be able to recycle your script with little changes, of course some adjustment might be needed. If you need to get input parameters you can use the Get-VstsInput command.

Over time I developed my set of scripts for demos and conferences, and some of them are in use in my homelab on a regular basis. One of them is for managing Azure Traffic Manager, and I realised that there is no Azure DevOps task for managing Traffic Manager on the marketplace! Thanks to the brilliant session Utkarsh did at the London Microsoft DevOps Meetup I decided to give a go at at converting that script.
So this is what I did to recycle my script in a task - beware: this post is a crash course on how to do that, and I don't think it is actually anything special. It is just an easy way of productively recycle some existing scripts in a good way. I haven't finished yet - as a good Product Owner I started with an MVP and I see there is more and more to add to it 👀 - but it is slowly coming together and I hope it can be useful to someone in the near future.
What you need to do is create the scaffolding with the tfx cli. from which you can start customising the script.

Then remove any reference to the JavaScript portion of the task - you are just recycling a PowerShell script so you don't need it! It will also save you time when debugging it as otherwise the runner defaults to the JavaScript entry-point. Needless to say, the name of the target script is going to be the name of your script.
Add the VstsTaskSdk module otherwise you are going to get odd errors out. Also, remove any versioning reference. The structure should be .../ps_modules/VstsTaskSdk. This is true for every module you are going to use:
Code-wise, keep the scaffolding as clean as you can, and add your script inside the try statement after the Trace-VstsEnteringInvocation $MyInvocation. You should be able to recycle your script with little changes, of course some adjustment might be needed. If you need to get input parameters you can use the Get-VstsInput command.